
How Microsoft Became the West's Distribution Channel for Chinese AI
A federal court ordered OpenAI to hand over 20 million user conversations. Microsoft and Nvidia are now moving AI onto the device, where Chinese models win.

In January, a federal court in New York ordered OpenAI to hand over 20 million ChatGPT conversations, de-identified, to the news organizations suing it for copyright infringement, and rejected the company’s argument that user privacy should narrow the request. The conversations could be produced for one reason: they existed on OpenAI’s servers. Every exchange a user believed was private had been retained, and a court decided who else could read it. The ruling is a precise illustration of what it means to run intelligence inside someone else’s data center. The record exists, and control over it sits with the provider and, in the end, the court.
This is the backdrop against which Microsoft and Nvidia moved the location of AI this month. At Build on June 2, Microsoft introduced a Windows system that runs large AI models directly on the machine, and it paired that with Nvidia’s RTX Spark chip, which ships this fall in laptops from Surface, Dell, ASUS, HP, Lenovo and MSI. A model running on the device needs no data center and no internet connection. There is no server-side transcript, because there is no server in the loop. The exchange happens on the hardware and stays there.
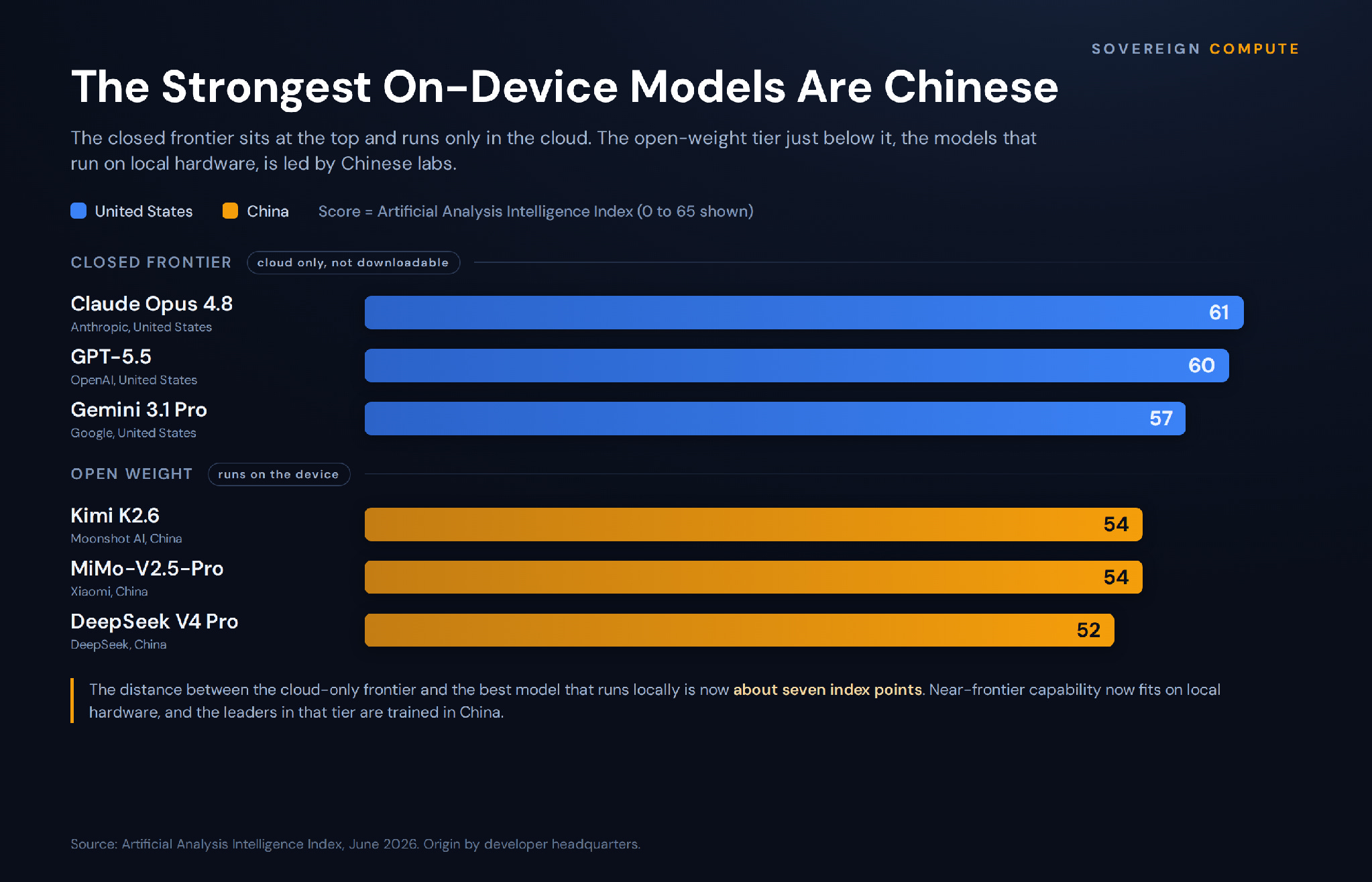
Artificial Analysis Intelligence Index, June 2026. Closed frontier models run only in the cloud; open-weight models run on local hardware.
The consequence turns on which models can run that way. The systems at the closed frontier, Anthropic’s Claude, OpenAI’s flagship GPT, Google’s Gemini, are not available for download; they stay in the cloud behind an account, and they still carry most production and customer-facing work. The models that run locally are open-weight, their files public and free to install. By independent 2026 benchmarks, the leading open-weight models now come from Chinese labs: DeepSeek, Moonshot’s Kimi, Zhipu’s GLM and Alibaba’s Qwen, ahead of Meta’s Llama and the smaller open releases from Google and OpenAI. Two years ago Llama set the open-weight pace; the lead has since moved to Beijing’s labs.
This is not confined to private users. Regulated industries are the natural buyers of local inference, since finance, healthcare, legal and government-adjacent work increasingly cannot send sensitive data to an external model under GDPR, HIPAA and the EU AI Act. The survey evidence points the same way, with 41 percent of enterprises planning to expand open-weight use and another 41 percent ready to switch from closed models once performance reaches parity. On-device hardware carries that local layer from the server room to the endpoint, where the most sensitive material already lives.
The strategic turn is what this does to the West’s main instrument against Chinese models. The restrictions in place apply to the hosted service. In 2025 Germany’s Berlin data protection authority concluded that DeepSeek’s app unlawfully transfers German users’ personal data to servers in China, where national security law gives the state access, and asked Apple and Google to remove it from their stores. Italy’s regulator had already ordered the company to stop processing Italian users’ data, and Australia and several US agencies barred the app from government devices. Each action rests on the same fact: the app sends what users type to infrastructure in China. An open-weight model downloaded and run on a local machine sends nothing anywhere. The transfer these bans were written to stop does not occur when the weights execute on a closed device, so the policy tool the West has relied on does not reach the on-device case. What remains is provenance. The training, behavior and content rules of these models are decided in China, and a growing share of private and regulated inference inside Western institutions can run on a strategic competitor’s model with no traffic for a regulator to inspect.
For two years sovereign AI has been governed at the central facility: the data center that can be located, the chips that can be licensed, the cloud account that can be subpoenaed. On-device inference moves a real share of capability outside all three. It offers a way to run AI on sensitive material with no retrievable trail, which is the OpenAI ruling read in reverse. It also gives the question of national AI capability a harder form, since the most capable portable models are trained by a strategic competitor and travel on consumer hardware that no border check and no export license reaches. The campuses keep rising, and they still matter. The device has become the second place sovereignty is decided, and it is the place current policy was not built to govern.
A note on independence: All opinions shared in this newsletter are my own and do not reflect the views of dmg events, ADIPEC, or any affiliated organizations. This is personal analysis, not institutional positioning.
Sources
OpenAI ordered to produce 20 million ChatGPT logs (Bloomberg Law) https://news.bloomberglaw.com/ip-law/openai-must-turn-over-20-million-chatgpt-logs-judge-affirms
Windows PCs accelerated by Nvidia RTX Spark (Microsoft) https://blogs.windows.com/windowsexperience/2026/05/31/introducing-a-powerful-new-chapter-for-windows-pcs-accelerated-by-nvidia-rtx-spark/
Model intelligence rankings (Artificial Analysis) https://artificialanalysis.ai/leaderboards/models
Germany asks Apple and Google to block DeepSeek (CNBC) https://www.cnbc.com/2025/06/27/germany-tells-apple-google-to-block-deepseek-ai-app.html
DeepSeek restrictions by country (Euronews) https://www.euronews.com/next/2025/06/27/german-official-urges-apple-and-google-to-ban-ai-company-deepseek-citing-privacy-concerns
Enterprise open-weight adoption trends (a16z, via Hatchworks) https://hatchworks.com/blog/gen-ai/open-source-vs-closed-llms-guide/